
分析是否有瓶颈(依据当前应用需求)
调优(把错误的调正确,把差的调到最好的)
系统的运行状况: CPU-> MEM ->DISK -> NETWORK -> 应用程序调优
性能优化
性能优化就是找到系统处理中的瓶颈以及去除这些的过程。
性能优化其实是对 OS 各子系统达到一种平衡的定义,这些子系统包括了:CPU ;Memory ;IO ;Network;
这些子系统之间关系是相互彼此依赖的,任何一个高负载都会导致其他子系统出现问题。
例如:
大量的网页调入请求导致内存队列的拥塞;
网卡的大吞吐量可能导致更多的 CPU 开销;
大量来自内存的磁盘写请求可能导致更多的 CPU 以及 IO 问题;
所以要对一个系统进行优化,查找瓶颈来自哪个方面是关键,虽然看似是某一个子系统出现问题,其实有可能是别的子系统导致的.
调优就像医生看病,因此需要你对服务器所有地方都了解清楚。
CPU状态相关工具
想要调优,想了解系统状态,通过命令和文件都可以反应当前CPU负载的相关情况
查看系统运行相关命令状况:
常用命令uptimehostnameuname -aidwhowhoamiwfree top
# uptime 15:12:46 up 2 days, 1:40, 1 user, load average: 0.00, 0.01, 0.05
uptime命令各个内容解释如下:
| 19:49:06 | 当前时间 |
| up 2 days | 系统运行时间 ,说明此服务器连续运行50天了 |
| 1 users | 当前登录用户数 |
| load average: 0.00, 0.01, 0.05 | 系统负载,即任务队列的平均长度。 三个数值分别为 1分钟、5分钟、15分钟前到现在的平均值。 |
负载的数字记得跟你的处理器有关:如果服务器的 CPU 为 1 核心,则 load average 中的数字 >=3 负载过高,如果服务器的 CPU 为 4 核心,则 load average 中的数字 >=12 负载过高。为什么?了解一下处理器处理进程的相关原理
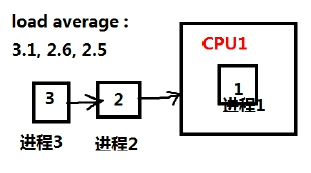
例如:上图,1个在运行,两个进程在排队,队列数包含运行进程,也就是三个进程,CPU已经处理不过来了,就意味着负载过高了!一般来说,一个在处理,一个在等待,那么我们认为负载正常,但是如果有一个已经在等待了,还有一个加入等待,那么证明CPU处理能力达到了瓶颈,负载以及过高了!
1,5,15系统平均负载1分钟的系统负载,指的是1分钟系统中持续运行的进程个数理论上:单核心,1分钟的系统平均负载不要超过3
/proc目录
通过/proc目录下的文件了解系统实施运行状态
cpuinfo[root@local ~]# cat /proc/cpuinfo //CPU参数processor : 0 #系统中逻辑处理核的编号。对于单核处理器,则课认为是其CPU编号,对于多核处理器则可以是物理核、或者使用超线程技术虚拟的逻辑核vendor_id : GenuineIntel #CPU制造商 cpu family : 6 #CPU产品系列代号model : 62 #CPU属于其系列中的哪一代的代号model name : Intel(R) Xeon(R) CPU E5-2650 v2 @ 2.60GHz #CPU属于的名字及其编号、标称主频stepping : 4 #CPU属于制作更新版本microcode : 1064 #BIOS相关cpu MHz : 2600.092 #CPU的实际使用主频cache size : 20480 KB #CPU二级缓存大小physical id : 0 #单个CPU的标号siblings : 1 #单个CPU逻辑物理核数core id : 0 #当前物理核在其所处CPU中的编号,这个编号不一定连续cpu cores : 8 #该逻辑核所处CPU的物理核数apicid : 0 #用来区分不同逻辑核的编号,系统中每个逻辑核的此编号必然不同,此编号不一定连续fpu : yes #是否具有浮点运算单元(Floating Point Unit)fpu_exception : yes #是否支持浮点计算异常cpuid level : 13 #执行cpuid指令前,eax寄存器中的值,根据不同的值cpuid指令会返回不同的内容wp : yes #表明当前CPU是否在内核态支持对用户空间的写保护(Write Protection)flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat clflush mmx fxsr sse sse2 ht syscall nx rdtscp lm constant_tsc up rep_good unfair_spinlock pni ssse3 cx16 sse4_1 sse4_2 popcnt aes hypervisor lahf_lm #当前CPU支持的功能bogomips : 5200.18 #在系统内核启动时粗略测算的CPU速度(Million Instructions Per Second)clflush size : 64 #每次刷新缓存的大小单位cache_alignment : 64 #缓存地址对齐单位address sizes : 46 bits physical, 48 bits virtual #访问地址空间位数power management: #对能源管理的支持有哪些……cpu cores : 8 #8核心……processor : 1……processor : 7
cmdline
cat /proc/cmdline //获取内核命令行参数ro root=UUID=94e4e384-0ace-437f-bc96-057dd64f42ee rd_NO_LUKS rd_NO_LVM LANG=en_US.UTF-8 rd_NO_MD SYSFONT=latarcyrheb-sun16 KEYBOARDTYPE=pc KEYTABLE=us rd_NO_DM rhgb quiet注意这里的/proc/cmdline和/etc/grub.conf的内容一样
# cat /etc/grub.conf# grub.conf generated by anaconda## Note that you do not have to rerun grub after making changes to this file# NOTICE: You do not have a /boot partition. This means that# all kernel and initrd paths are relative to /, eg.# root (hd0,0)# kernel /boot/vmlinuz-version ro root=/dev/xvda1# initrd /boot/initrd-[generic-]version.img#boot=/dev/xvdadefault=0timeout=5splashimage=(hd0,0)/boot/grub/splash.xpm.gzhiddenmenutitle CentOS (2.6.32-573.8.1.el6.x86_64) root (hd0,0) kernel /boot/vmlinuz-2.6.32-573.8.1.el6.x86_64 ro root=UUID=94e4e384-0ace-437f-bc96-057dd64f42ee rd_NO_LUKS rd_NO_LVM LANG=en_US.UTF-8 rd_NO_MD SYSFONT=latarcyrheb-sun16 crashkernel=auto KEYBOARDTYPE=pc KEYTABLE=us rd_NO_DM rhgb quiet initrd /boot/initramfs-2.6.32-573.8.1.el6.x86_64.imgtitle CentOS (2.6.32-431.23.3.el6.x86_64) root (hd0,0) kernel /boot/vmlinuz-2.6.32-431.23.3.el6.x86_64 ro root=UUID=94e4e384-0ace-437f-bc96-057dd64f42ee rd_NO_LUKS rd_NO_LVM LANG=en_US.UTF-8 rd_NO_MD SYSFONT=latarcyrheb-sun16 crashkernel=auto KEYBOARDTYPE=pc KEYTABLE=us rd_NO_DM rhgb quiet initrd /boot/initramfs-2.6.32-431.23.3.el6.x86_64.img
diskstats
cat /proc/diskstats //相当于fdisk -l 8 0 sda 6981 5394 439682 76909 750 2301 24402 107850 0 34562 184763 8 1 sda1 591 236 4632 530 3 0 18 88 0 564 618 8 2 sda2 5884 5126 430746 75212 747 2301 24384 107762 0 34085 182980 8 3 sda3 332 31 2904 1051 0 0 0 0 0 1050 1050 11 0 sr0 53 47 536 128 0 0 0 0 0 115 128
# fdisk -lDisk /dev/sda: 21.5 GB, 21474836480 bytes255 heads, 63 sectors/track, 2610 cylindersUnits = cylinders of 16065 * 512 = 8225280 bytesSector size (logical/physical): 512 bytes / 512 bytesI/O size (minimum/optimal): 512 bytes / 512 bytesDisk identifier: 0x00092896 Device Boot Start End Blocks Id System/dev/sda1 * 1 26 204800 83 LinuxPartition 1 does not end on cylinder boundary./dev/sda2 26 1332 10485760 83 Linux/dev/sda3 1332 1462 1048576 82 Linux swap / Solaris这个文件列出字符和块设备的主设备号,以及分配到这些设备号的设备名称。
filesystems
查看当前系统中可以支持的文件系统类型 ,这个文件列出可供使用的文件系统类型,一种类型一行。虽然它们通常是编入内核的文件系统类型,但该文件还可以包含可加载的内核模块加入的其它文件系统类型。 nodev 表示支持但不存在,没使用
cat /proc/filesystems……nodev ramfsnodev hugetlbfs #未使用 iso9660 #使用中nodev pstorenodev mqueue ext4 #使用中nodev vmhgfsnodev fuse fuseblk #使用中nodev fusectlnodev autofs
mdstat
查看 raid 设备信息 这个文件包含了由 md 设备驱动程序控制的 RAID 设备信息
# cat /proc/mdstatPersonalities (个性): unused devices:
modules
lsmod就是从这里读取数据的 ,查看当前内核加载了哪些动态模块:[root@local ~]# cat /proc/modulesnfs 228929 13 - Live 0xf929e000 ----------------------- 模块名,占用内存,加载次数,是否可用,起始地址?
mounts
# cat /proc/mounts这个文件以/etc/mtab文件的格式给出当前系统所安装的文件系统信息。这个文件也能反映出任何手工安装从而在/etc/mtab文件中没有包含的文件系统。rootfs / rootfs rw 0 0proc /proc proc rw,relatime 0 0sysfs /sys sysfs rw,relatime 0 0devtmpfs /dev devtmpfs rw,relatime,size=491832k,nr_inodes=122958,mode=755 0 0devpts /dev/pts devpts rw,relatime,gid=5,mode=620,ptmxmode=000 0 0tmpfs /dev/shm tmpfs rw,relatime 0 0/dev/sda2 / ext4 rw,relatime,barrier=1,data=ordered 0 0/proc/bus/usb /proc/bus/usb usbfs rw,relatime 0 0/dev/sda1 /boot ext4 rw,relatime,barrier=1,data=ordered 0 0/dev/sr0 /media iso9660 ro,relatime 0 0none /proc/sys/fs/binfmt_misc binfmt_misc rw,relatime 0 0vmware-vmblock /var/run/vmblock-fuse fuse.vmware-vmblock rw,nosuid,nodev,relatime,user_id=0,group_id=0,default_permissions,allow_other 0 0/etc/auto.misc /misc autofs rw,relatime,fd=7,pgrp=2121,timeout=300,minproto=5,maxproto=5,indirect 0 0-hosts /net autofs rw,relatime,fd=13,pgrp=2121,timeout=300,minproto=5,maxproto=5,indirect 0 0gvfs-fuse-daemon /root/.gvfs fuse.gvfs-fuse-daemon rw,nosuid,nodev,relatime,user_id=0,group_id=0 0 0
partitions
分区表信息
cat /proc/partitionsmajor minor #blocks name 8 0 20971520 sda 8 1 204800 sda1 8 2 10485760 sda2 8 3 1048576 sda3
进程ID
ls /proc/目录下还有很多数字命名的目录,这些都是进程的ID1 1926 22 2566 27 2784 286 35 52 76 filesystems mtrr10 1941 2280 257 270 2785 2860 36 53 77 fs net1035 1952 23 258 271 2788 2882 37 54 78 interrupts pagetypeinfo1036 1957 2360 259 272 279 2885 38 55 8 iomem partitions1083 196 2366 26 2726 2791 29 381 56 80 ioports sched_debug可以通过进程的ID查到程序的运行绝对路径[root@local ~]# ll /proc/2885/exelrwxrwxrwx 1 root root 0 Dec 28 11:25 /proc/2885/exe -> /usr/libexec/pulse/gconf-helper
进程
进程的筛选有助于我们了解系统当前的运行状态,以及在后期调优的时候对目前的状态做一个参照数值!
进程列表ps命令
ps 命令:只对具体进程进行观测:# ps -aux
5 个主要进程状态:
S --> 睡眠
R --> 正在运行或准备运行
Z --> 僵尸进程
D --> 不可中断的睡眠进程
T --> 停止或者被追踪的进程
L --> (内存锁,防止交换--解决 swap 信息泄漏,锁住内存,防止交换)
s --> session header 父子/父子 ----> 父迚程,引导进程
+ --> 前台进程组 表示是一组进程,而不是一个进程
l --> 进程,线程
< --> 高优先级进程
N --> 低优先级进程
按内存对进程排序
# ps -aux --sort -rss //去掉-rss是升序Warning: bad syntax, perhaps a bogus '-'? See /usr/share/doc/procps-3.2.8/FAQUSER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMANDroot 2475 1.2 3.8 169112 38184 tty1 Ss+ 11:08 0:16 /usr/bin/Xorg :0 -nr -verbose -root 2764 0.2 2.2 538540 22436 ? S 11:10 0:03 nautilusroot 3013 0.0 2.1 402184 21956 ? S 11:10 0:00 /usr/bin/gnote --panel-applet -root 2882 0.0 1.9 324388 19724 ? S 11:10 0:00 python /usr/share/system-configroot 2791 0.2 1.7 307692 18060 ? S 11:10 0:03 /usr/lib/vmware-tools/sbin64/vmroot 3017 0.0 1.6 466092 16864 ? S 11:10 0:00 /usr/libexec/clock-applet --oaf
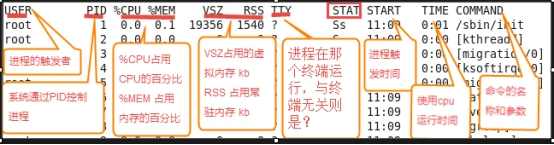
# ps -aux --sort rss //升序ps -aux --sort -pcpu //按CPU降序,去掉-号为升序man ps //排序条件帮助 KEY LONG DESCRIPTION c cmd simple name of executable C pcpu cpu utilization f flags flags as in long format F field g pgrp process group ID G tpgid controlling tty process group ID j cutime cumulative user time J cstime cumulative system time k utime user time m min_flt number of minor page faults M maj_flt number of major page faults n cmin_flt cumulative minor page faults N cmaj_flt cumulative major page faults o session session ID p pid process ID P ppid parent process ID r rss resident set size R resident resident pages s size memory size in kilobytes S share amount of shared pages t tty the device number of the controlling tty T start_time time process was started
top命令
找出占用CPU时间比较多的进程 (这个命令本身就很消耗CPU时间的)
toptop - 11:36:46 up 28 min, 2 users, load average: 0.00, 0.00, 0.00Tasks: 218 total, 1 running, 216 sleeping, 1 stopped, 0 zombieCpu(s): 0.9%us, 0.5%sy, 0.0%ni, 98.6%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%stMem: 1004412k total, 564072k used, 440340k free, 28580k buffersSwap: 1048568k total, 0k used, 1048568k free, 270772k cached PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 2475 root 20 0 197m 37m 8968 S 4.3 3.8 0:22.77 Xorg 3052 root 20 0 290m 14m 10m S 2.0 1.5 0:09.91 gnome-terminal 2750 root 20 0 429m 14m 10m S 0.7 1.4 0:01.15 metacity 21 root 20 0 0 0 0 S 0.3 0.0 0:01.45 events/2 0.0%us:用户态 0.0%sy:内核态0.0%ni:优先级切换97.6%id:CPU 空闲2.3%wa:等待,IO 输入输出等待0.0%hi:硬中断0.1%si:软中断0.0%st:CPU 偷窃时间。 如开启虚拟机会出现这种情况TOP命令的排序:M内存排序,Pcup排序,<>前后翻页查看进程
动态查看进程
# find / 另开一个终端执行# vim a.txt 再开一个终端执行# ps -aux | grep find //拿到PID# ps -aux | grep a.txt //拿到PID# top -p 3284,3259 //动态查看,-p=pidtop - 11:47:16 up 39 min, 4 users, load average: 0.09, 0.07, 0.02Tasks: 2 total, 0 running, 2 sleeping, 0 stopped, 0 zombieCpu(s): 5.9%us, 5.6%sy, 0.0%ni, 88.6%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%stMem: 1004412k total, 698264k used, 306148k free, 99668k buffersSwap: 1048568k total, 0k used, 1048568k free, 273068k cached PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 3284 root 20 0 109m 1296 936 S 12.3 0.1 0:01.90 find 3259 root 20 0 140m 3940 2652 S 0.0 0.4 0:00.43 vim
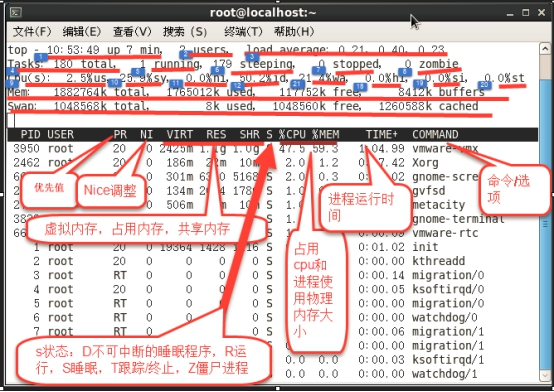
1: 10:53:29表示系统给当前时间,up 7 min表示系统运行了多长时间了(分)2: 当前系统登录的用户数3: 系统负载平均值,三个值分别为1,5,15分钟的平均值(除于CPU个数不大于1就没有什么影响)4:多少个任务在运行,总共多少个进程5:正在运行的进程数6:休眠的进程数7:停止的进程数8:僵尸进程9:CPU给用户分配了多少10:CPU给系统分配了多少,内核中的进程占用CPU的百分比11:调优后进程所占有的CPU百分比12:空闲进程百分比21:等待 wait18:硬中断19:软中断20:cpu偷窃占用最后两行内容是:物理内存总共多少,用了多少,还剩多少,缓存多少Swap总共多少,用了多少,还剩多少,缓存多少Notes:top命令后,敲d可以更改刷新时间(默认3s刷新一次) 空格键立即刷新 m按内存排序 p按CPU排序 q退出kill 控制进程常见信号HUP 重新加载配置文件,类似重启,立即应用新的配置文件 1INT 和CTRL+C,用于通知前台进程组终止进程 2Kill 强行中断 9Stop 和Ctrl+Z 19Eg: #kill -9 7678#killall httpd 与 #pkill httpd 直接杀死httpd相关所有进程#pidof httpd 查询进程状态和查询进程的pid
mpstat命令
这个命令需要安装,由软件包sysstaat提供
# rpm -ivh /media/RHEL_6.5\ x86_64\ Disc\ 1/Packages/sysstat-9.0.4-22.el6.x86_64.rpm //此软件包,包括很多查看系统状态的软件包
mpstat //所有CPU综合信息Linux 2.6.32-431.el6.x86_64 (xuegod63.cn) 12/28/2015 _x86_64_ (4 CPU) 11…… AM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle11…… AM all 0.35 0.00 0.55 0.64 0.00 0.03 0.00 0.00 98.44%user 表示处理用户进程所使用 CPU 的百分比。用户进程是用于应用程序(如 Oracle 数据库)的非内核进程。 %nice 表示使用 nice 命令对进程进行降级时 CPU 的百分比。在之前的部分中已经对 nice 命令进行了介绍。简单来说,nice 命令更改进程的优先级。 %sys 表示内核进程使用的 CPU 百分比 %iowait 表示等待进行 I/O 所使用的 CPU 时间百分比 %irq 表示用于处理系统中断的 CPU 百分比 %soft 表示用于软件中断的 CPU 百分比 %idle 显示 CPU 的空闲时间 %intr/s 显示每秒 CPU 接收的中断总数 [root@xuegod63 ~]# mpstat -P ALL //所有CPU运行状态Linux 2.6.32-431.el6.x86_64 (xuegod63.cn) 12/28/2015 _x86_64_ (4 CPU) 11:57:50 AM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle11:57:50 AM all 0.31 0.00 0.48 0.56 0.00 0.03 0.00 0.00 98.6111:57:50 AM 0 0.74 0.00 1.00 1.72 0.01 0.02 0.00 0.00 96.5111:57:50 AM 1 0.31 0.00 0.57 0.26 0.00 0.09 0.00 0.00 98.7711:57:50 AM 2 0.13 0.00 0.27 0.16 0.00 0.01 0.00 0.00 99.4411:57:50 AM 3 0.07 0.00 0.11 0.10 0.00 0.00 0.00 0.00 99.72
top //执行之后按数字键1 看到内容相似top - 11:58:57 up 50 min, 4 users, load average: 0.02, 0.01, 0.00Tasks: 219 total, 1 running, 217 sleeping, 1 stopped, 0 zombieCpu0 : 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%stCpu1 : 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%stCpu2 : 0.0%us,100.0%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%stCpu3 : 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%stMem: 1004412k total, 696616k used, 307796k free, 99912k buffers
mpstat -P ALL 1 100 //一秒钟刷新一次 连续刷新 100 次
内存运行状态相关工具
通用查询工具,内存信息查询工具
free命令
free -m //MB单位 total used free shared buffers cachedMem: 980 880 100 0 87 508-/+ buffers/cache: 285 695Swap: 1023 0 1023buffers #内存从磁盘读出的内容cached #内存需要写入磁盘的内容当物理内存不够用的时候,内核会把非活跃的数据清空。
sync //内存和硬盘数据同步# echo 3 > /proc/sys/vm/drop_caches 清空缓存执行find会发现buffers增加,dd if=/dev/zero of=a.txt bs=1M count=1024会有cached增加
meminfo文件
通过/proc/meminfo 文件夹,查看非活跃的内存: /proc 文件系统下的多种文件提供的系统信息不是针对某个特定经常的,而是能够在整个系统范围的上下文中使用。可以使用的文件随系统配置的变化而变。
# cat /proc/meminfoMemTotal: 1004412 kB #总内存MemFree: 75376 kB #空闲大小Buffers: 21524 kB #用来给文件做缓冲大小Cached: 621092 kB #被高速缓冲存储器使用大小SwapCached: 8 kB #被高速缓冲存储器的交换空间大小Active: 95520 kB #在活跃使用中的缓冲或高速缓冲存储器页面文件的大小,活跃内存Inactive: 709552 kB #在不经常使用中的缓冲或高速缓冲存储器页面文件的大小,非活跃内存Active(anon): 14960 kB #anon不久的意思,刚刚缓存的活跃内存Inactive(anon): 152148 kB #刚刚缓存的不活跃内存Active(file): 80560 kB #于文件相关的活跃内存Inactive(file): 557404 kB #于文件相关的不活跃内存Unevictable: 0 kB #等待物理内回收大小Mlocked: 0 kB #被锁定的内存大小SwapTotal: 1048568 kB #交换空间总大小SwapFree: 1048560 kB #空闲交换空间Dirty: 12 kB #等待被写回到磁盘的大小Writeback: 0 kB #正在被写回的大小AnonPages: 162464 kB #未映射的页的大小Mapped: 64628 kB #设备和文件映射的大小Shmem: 4636 kB #共享内存大小Slab: 72996 kB #内核数据结构缓存的大小,可减少申请和释放内存带来的消耗SReclaimable: 38920 kB #可收回slab的大小SUnreclaim: 34076 kB #不可收回的slab的大小KernelStack: 2520 kB #内核调试内存大小PageTables: 18528 kB #管理内存分页的索引表的大小NFS_Unstable: 0 kB #不稳定页表的大小……VmallocTotal: 34359738367 kB #虚拟内存大小VmallocUsed: 153316 kB #已经被使用的虚拟内存大小VmallocChunk: 34359578676 kBHardwareCorrupted: 0 kBAnonHugePages: 34816 kBHugePages_Total: 0 #//大页面的分配HugePages_Free: 0……注:当内存不够用时,kernel总是把不活跃的内存交换到swap空间。如果inactive内存多时,加swap空间可以解决问题,而active多,则考虑加内存。
vmstat命令
命令是最常见的Linux/Unix监控工具,可以展现给定时间间隔的服务器的状态值,包括服务器的CPU使用率,MEM内存使用,VMSwap虚拟内存交换情况,IO读写情况。
使用vmstat可以看到整个机器的CPU,内存,IO的使用情况,而不是单单看到各个进程的CPU使用率和内存使用率。 比top命令节省资源。
注:当机器运行比较慢时,建议大家使用vmstat查看运行状态,不需要使用top,因top使用资源比较多
vmstatprocs -----------memory---------- ---swap-- -----io---- --system-- -----cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 8 61632 24060 619856 0 0 28 42 47 52 0 0 99 1 0 r 运行状态的进程个数 。展示了正在执行和等待cpu资源的任务个数。当这个值超过了cpu个数,就会出现cpu瓶颈。b 不可中断睡眠 正在进行i/o等待--阻塞状态的进程个数 进程读取外设上的数据,等待时free 剩余内存,D位是KBbuffers #内存从磁盘读出的内容cached #内存需要写入磁盘的内容si swapin swap换入到内存so swapout 内存换出到swap 换出的越多,内存越不够用bi blockin 从硬盘往内存读。 D位是块。 把磁盘中的数据读入内存bo blockout 从内存拿出到硬盘 (周期性的有值) 写到硬盘注:#判断是读多还是写多,是否有i/o瓶颈in 系统的中断次数,cpu调度的次数多cs 每秒的上下文切换速度注:如果这个数据比较大,说明有大并发的进程或线程在运行。 这种情况下,一般会用大理网络访问请求。Us 用户进程执行消耗cpu时间(user time) us的值比较高时,说明用户进程消耗的cpu时间多,但是如果长期超过50%的使用,那么我们就该考虑优化程序算法或其他措施了Sy 系统进程消耗cpu时间(system time) sys的值过高时,说明系统内核消耗的cpu资源多,这个不是良性的表现,我们应该检查原因。Id 空闲时间(包括IO等待时间) wa 等待IO时间 Wa过高时,说明io等待比较严重,这可能是由于磁盘大量随机访问造成的,也有可能是磁盘的带宽出现瓶颈。
| 类别 | 项目 | 含义 | 说明 |
| Procs(进程) | r | 等待执行的任务数 | 展示了正在执行和等待cpu资源的任务个数。当这个值超过了cpu个数,就会出现cpu瓶颈。 |
| B | 等待IO的进程数量 | ||
| Memory(内存) | swpd | 正在使用虚拟的内存大小,D位k | |
| free | 空闲内存大小 | ||
| buff | 已用的buff大小,对块设备的读写进行缓冲 | ||
| cache | 已用的cache大小,文件系统的cache | ||
| inact | 非活跃内存大小,即被标明可回收的内存,区别于free和active | 具体含义见:概念补充(当使用-a选项时显示) | |
| active | 活跃的内存大小 | 具体含义见:概念补充(当使用-a选项时显示) | |
| Swap | si | 每秒从交换区写入内存的大小(D位:kb/s) | |
| so | 每秒从内存写到交换区的大小 | ||
| IO | bi | 每秒读取的块数(读磁盘) | 现在的Linux版本块的大小为1024bytes |
| bo | 每秒写入的块数(写磁盘) | ||
| system | in | 每秒中断数,包括时钟中断 | 这两个值越大,会看到由内核消耗的cpu时间会越多 |
| cs | 每秒上下文切换数 | ||
| CPU(以百分比表示) | Us | 用户进程执行消耗cpu时间(user time) | us的值比较高时,说明用户进程消耗的cpu时间多,但是如果长期超过50%的使用,那么我们就该考虑优化程序算法或其他措施了 |
| Sy | 系统进程消耗cpu时间(system time) | sys的值过高时,说明系统内核消耗的cpu资源多,这个不是良性的表现,我们应该检查原因。 | |
| Id | 空闲时间(包括IO等待时间) | ||
| wa | 等待IO时间 | Wa过高时,说明io等待比较严重,这可能是由于磁盘大量随机访问造成的,也有可能是磁盘的带宽出现瓶颈。 |
vmstat 1 20 //每1s更新一次,更新20次